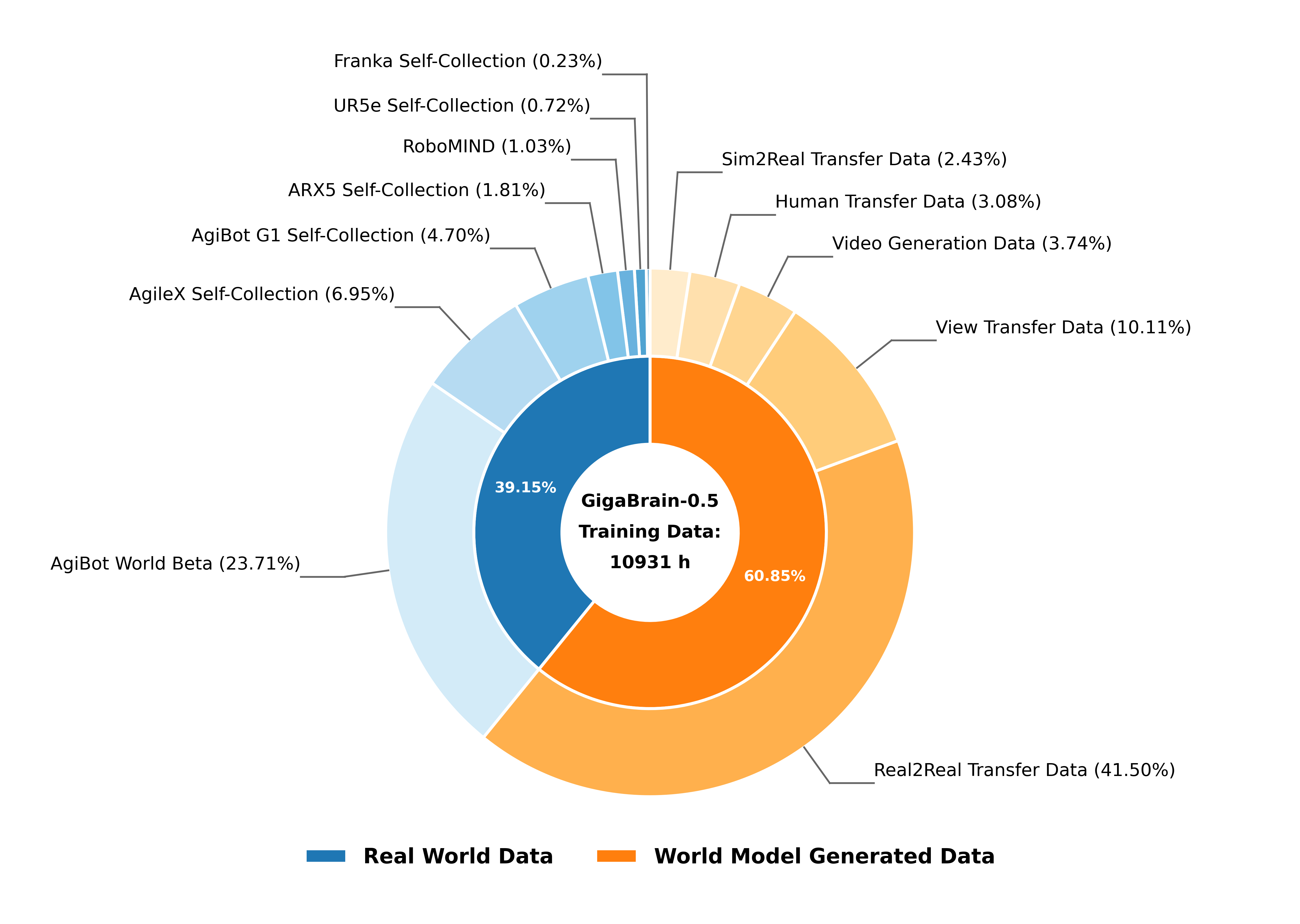
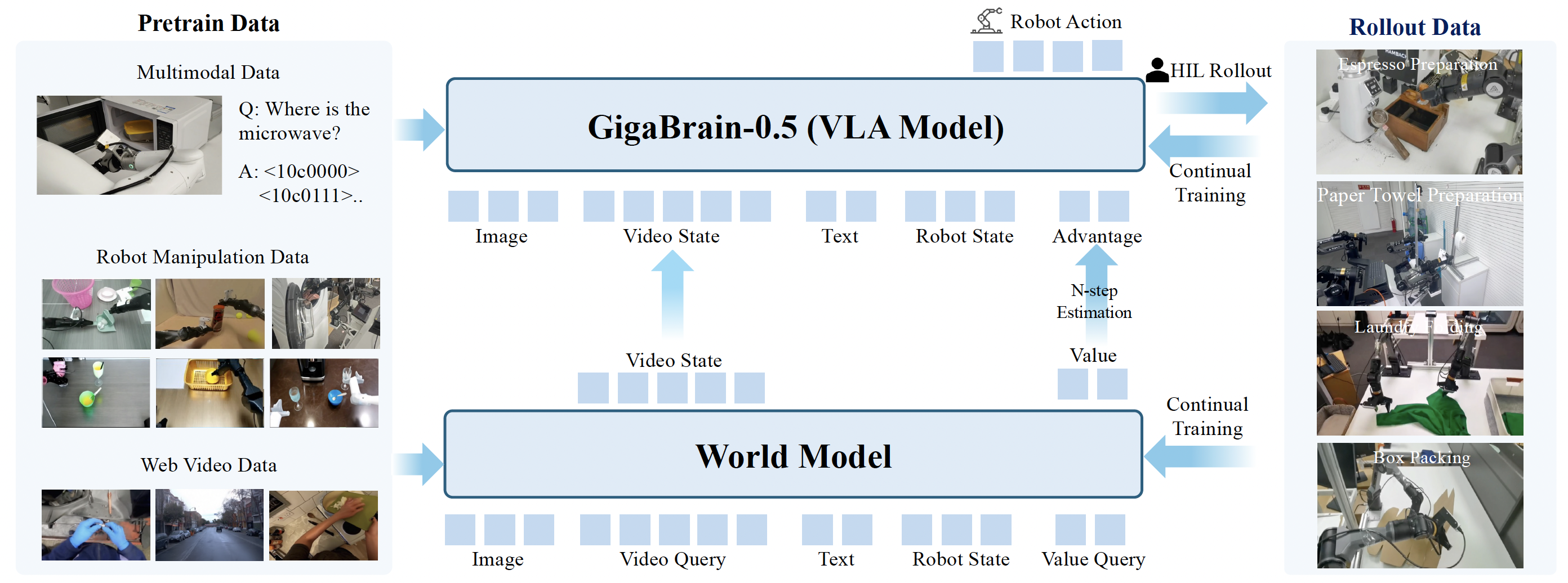
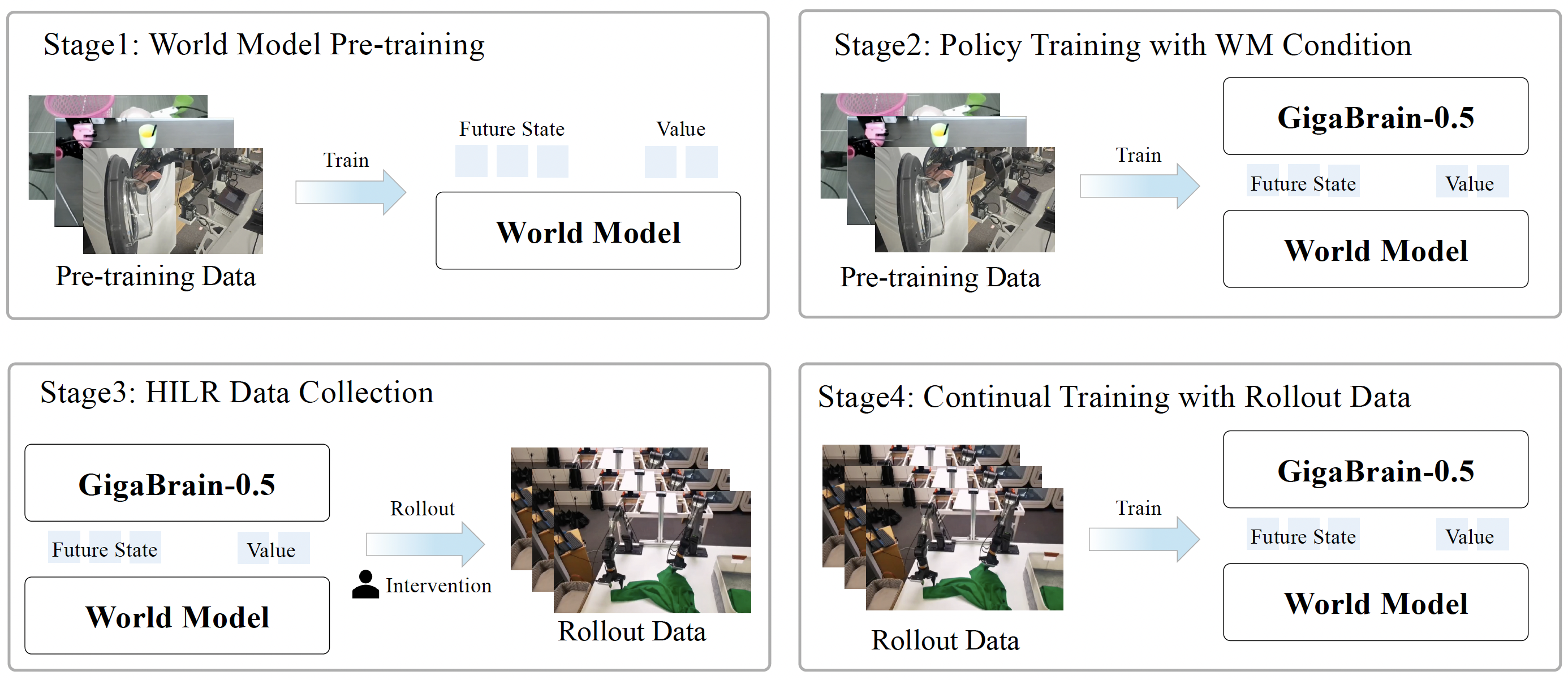
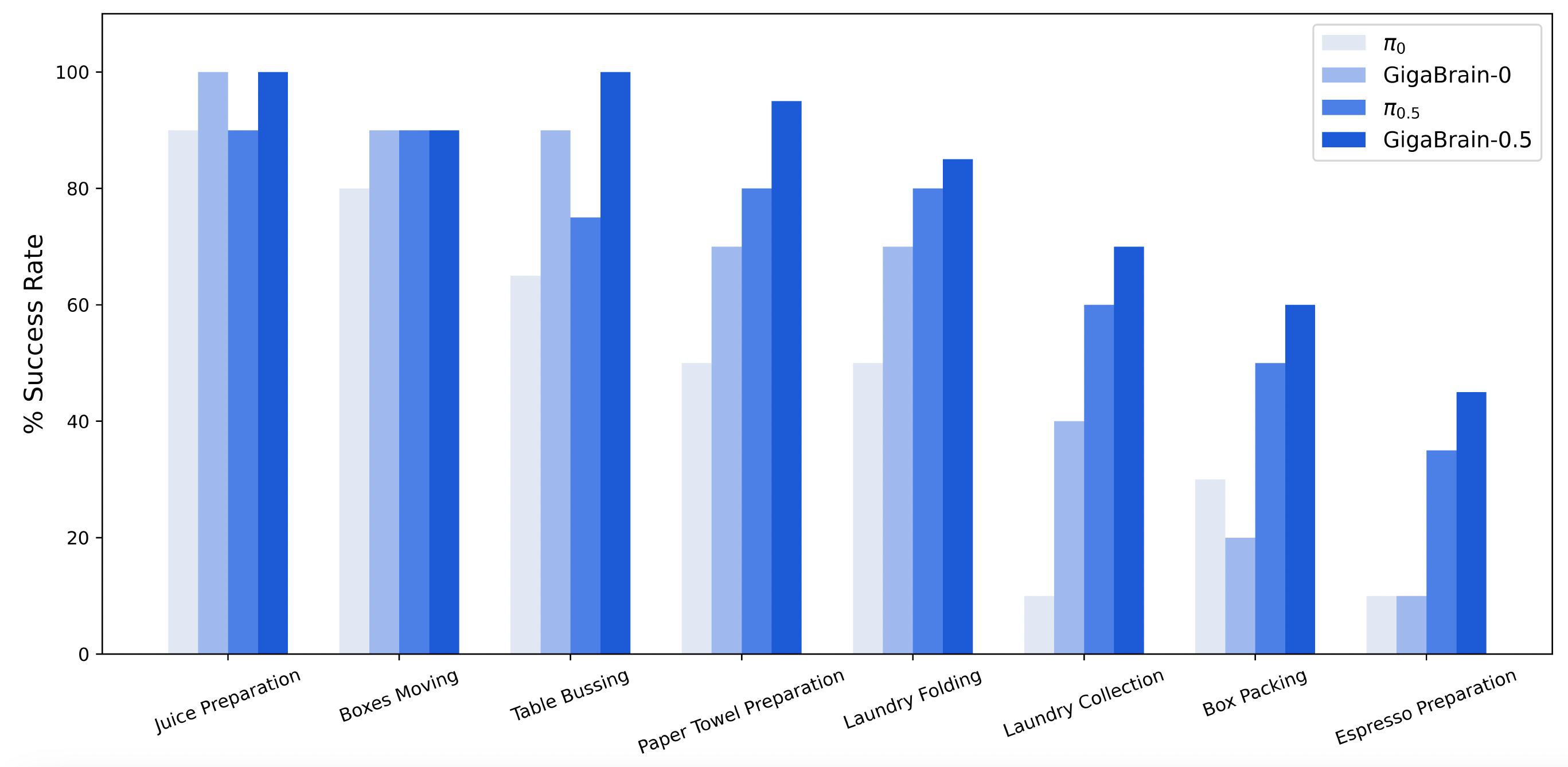
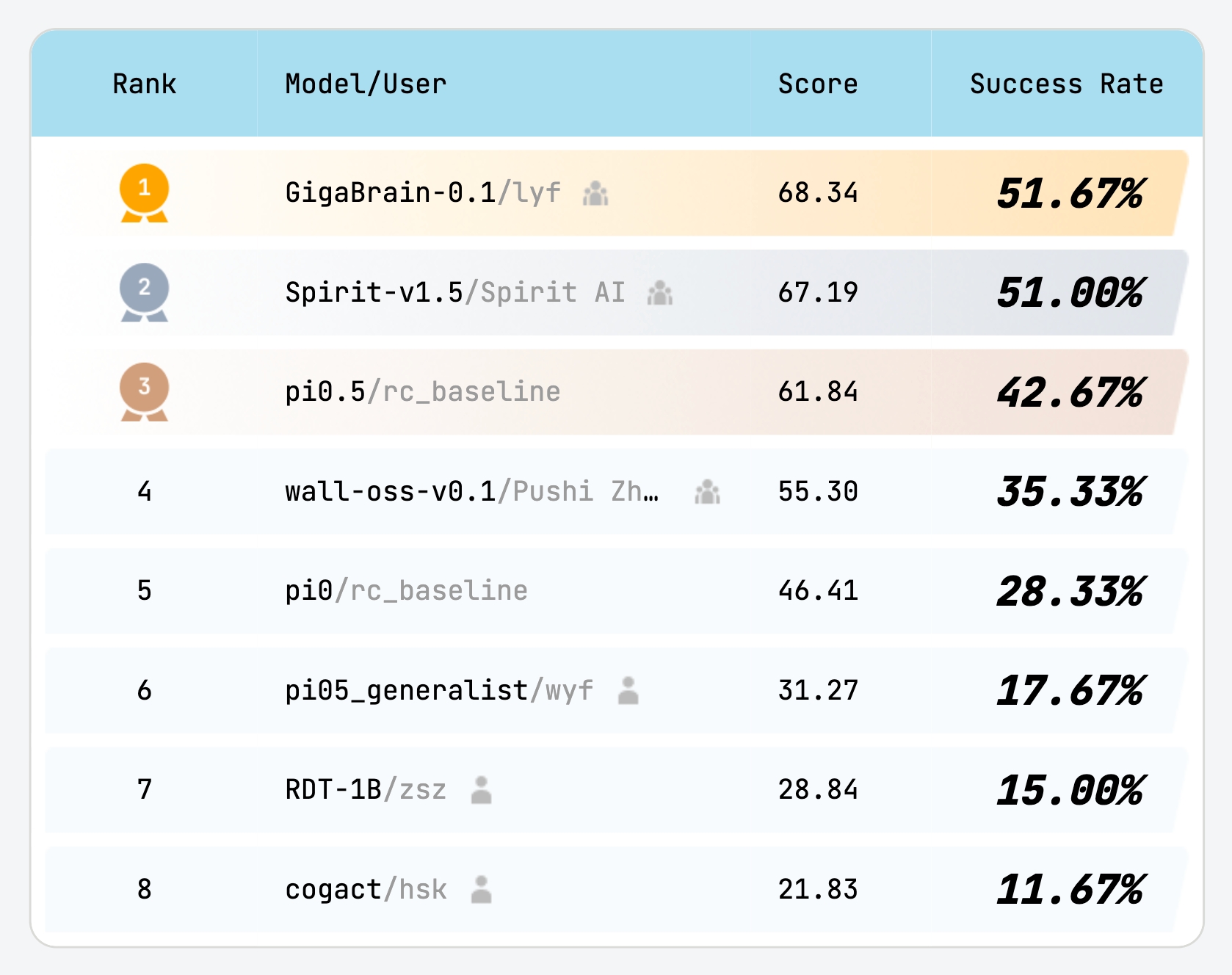
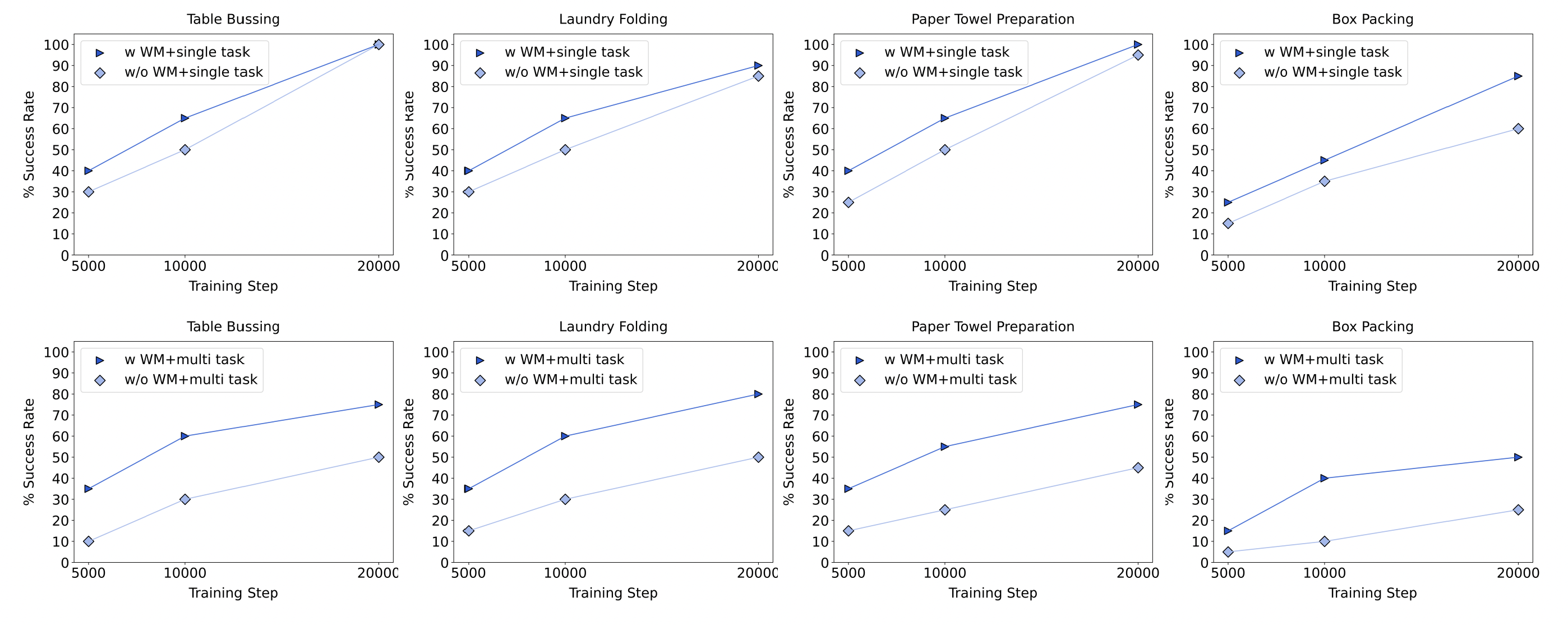
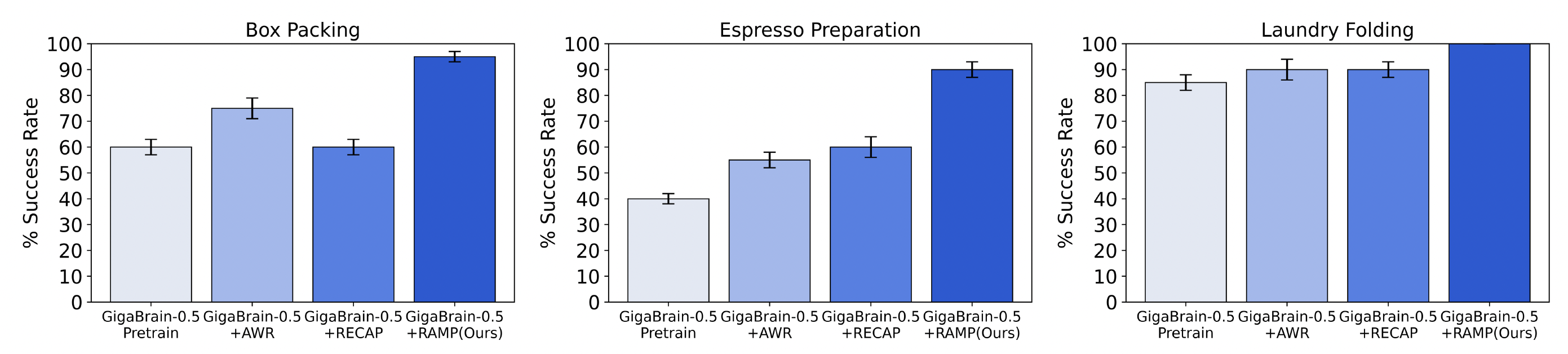
Vision-language-action (VLA) models that directly predict multi-step action chunks from current observations face inherent limitations due to constrained scene understanding and weak future anticipation capabilities. In contrast, video world models pre-trained on web-scale video corpora exhibit robust spatiotemporal reasoning and accurate future prediction, making them a natural foundation for enhancing VLA learning. Therefore, we propose GigaBrain-0.5M*, a VLA model trained via world model-based reinforcement learning. Built upon GigaBrain-0.5, which is pre-trained on over 10,000 hours of robotic manipulation data, whose intermediate version currently ranks first on the international RoboChallenge benchmark. GigaBrain-0.5M* further integrates world model-based reinforcement learning via RAMP (Reinforcement leArning via world Model-conditioned Policy) to enable robust cross-task adaptation. Empirical results demonstrate that RAMP achieves substantial performance gains over the RECAP baseline, yielding improvements of approximately 30% on challenging tasks including Laundry Folding, Box Packing, and Espresso Preparation. Critically, GigaBrain-0.5M* exhibits reliable long-horizon execution, consistently accomplishing complex manipulation tasks without failure.
直接从当前观测预测多步动作块的视觉-语言-动作(VLA)模型,由于场景理解受限且未来预测能力较弱,存在先天局限。相比之下,在大量视频语料上预训练的视频世界模型具备更强的时空推理与未来预测能力,是提升 VLA 学习的先验模型。因此,我们提出 GigaBrain-0.5M*:通过世界模型自我进化的VLA大模型。该模型基于 GigaBrain-0.5(在超过 10,000 小时机器人操作数据上预训练,其中间迭代的模型版本目前在国际 RoboChallenge 榜单排名第一)。GigaBrain-0.5M* 进一步通过 RAMP(Reinforcement leArning via world Model-conditioned Policy)引入基于世界模型的强化学习,实现稳健的跨任务适应。实验表明,RAMP 相比 RECAP 基线在 Laundry Folding、Box Packing、Espresso Preparation 等挑战任务上带来约 30% 的提升。更关键的是,GigaBrain-0.5M* 具备可靠的长时程执行能力,能够稳定完成复杂操作任务。